šfĄĮĖ▀┐╔ė├Ż¼┐┤╣┘éāĢ■ŽļĄĮ║▄ČÓĘĮ░ĖŻ¼ę▓įS╩ŪūįėH╔ĒĮøÜv▀^ŽĄĮyÅ─å╬ÖCūā│╔Ė▀┐╔ė├Ą─═┤┐Ó▀^│╠Ż¼ę▓įSėąĄ─┐┤╣┘ų╗╩Ūį┌ūį╝║Ą─╠ōÖC╔Ž┤ŅĮ©▀^£yįćĄ─═µŠ▀ĪŻĮ±╠ņ▒ŠŲ¬ė├╬ęūį╝║Ą─šµīŹĮøÜvĮo┤¾╝ęųv╩÷Ż¼▓╗╣▄į§├┤śėīŹæ║═£yįć═µ╦Ż▀Ć╩Ū║▄┤¾Ą─ģ^äeĄ─ŻĪ┐╔─▄─ŃėXĄ├┤ŅĮ©ę╗╠ūĖ▀┐╔ė├ĘĮ░Ė║▄║åå╬Ż¼┼õų├┼õų├Š═OK┴╦Ż¼Ą½į┌šµš²Ą─Å═ļsŽĄĮyųąę╗ŪąŠ═ø]ėą─Ū├┤▌p╦╔┴╦ŻĪ
╬─š┬ų„ę¬ųv╩÷╔²╝ē▓ó┤ŅĮ©AlwaysOnĖ▀┐╔ė├Ą─▀^│╠Ż¼ęįīŹ╩®Ą─╦╝┬Ę×ķų„ĪŻ╬─ųą▓óø]ėą┤ŅĮ©╝»╚║Ą─▓Į¾EŻ¼┤ŅĮ©▓Į¾EšłūįąąīW┴Ģ(éĆ╚╦šJ×ķĢ■┤ŅĮ©┐╔ė├ĮM▓ó▓╗╩ŪĻPµIŻ¼Č°ę╗ŽĄ┴ąĄ─š{čą╝Ü╣Ø▓┼╩ŪĒŚ─┐│╔╣”Ą─ĻPµI)ĪŻ
▒│Š░
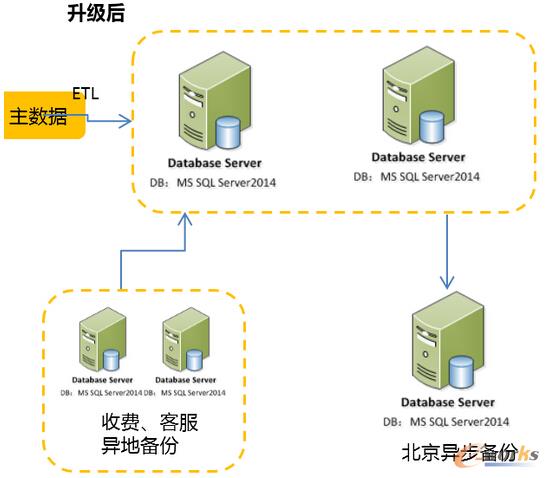
┐═æ¶Ą─¼FėąĘĮ░Ė╩Ūę╗╠ū╩╣ė├░l▓╝ėåķåśŗĮ©Ą─ūxīæĘųļxĘĮ░ĖŻ¼┐é¾wüĒšfŽĄĮyśŗĮ©Ą─║▄▓╗ÕeĪŻę▓╩Ūį┌SQL2012ų«Ū░║▄│ŻęŖĄ─ę╗╠ū╝▄śŗĪŻ
╝▄śŗłD╚ńŽ┬Ż║
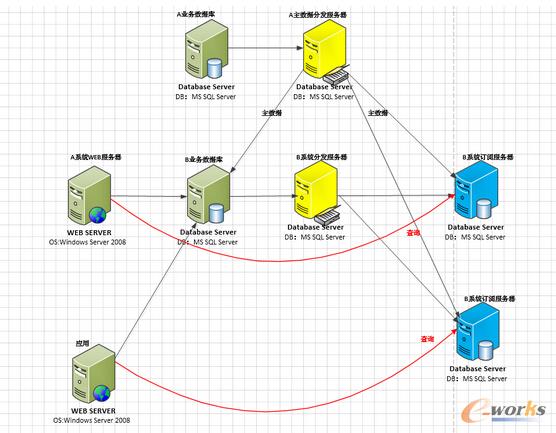
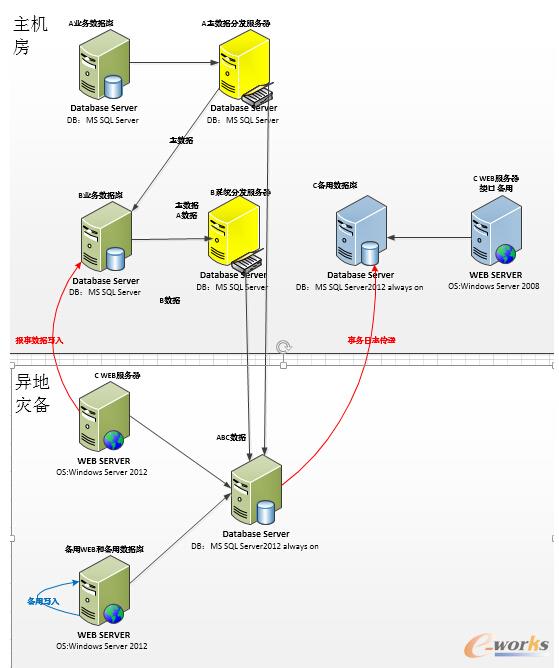
┐═æ¶Ą─ąĶŪ¾Ż║SQL server 2008 R2 ╔²╝ēĄĮSQL SERVER 2014 ╩╣ė├AlwaysOn ╠µōQ¼Fėą░l▓╝ėåķå╝▄śŗĪŻīŹ¼F▒ŠĄžĖ▀┐╔ė├ĪóūxīæĘųļxŻ¼«ÉĄž×─éõĄ╚Ż¼▓óæ¬ė├▓┐Ęų2014Ą─ą┬╣”─▄Ż¼╚ńā╚┤µā×╗»▒ĒĄ╚╠ß╔²ŽĄĮyąį─▄║═▓ó░l─▄┴”Ą╚ĪŻ
Ū░Ų┌š{čą
öĄō■╩š╝»
Ū░Ų┌ī”ŽĄĮyĄ─┴╦ĮŌ║▄ųžę¬ŻĪ─Ū├┤į§├┤śėī”ŽĄĮyėąę╗éĆ│§▓Įų▒ė^▓óŪęįö╝ÜĄ─┴╦ĮŌ─žŻ┐ė├─_▒Š╩š╝»Ż┐▀@╩ŪĢr║“Š═¾w¼F│÷╣żŠ▀Ą─īŻśI║═ģfū„ārųĄĪŻ╣żė¹╔ŲŲõ╩┬Ż¼▒žŽ╚└¹ŲõŲ„ŻĪ
┤_Č©ĘĮ░Ė
═©▀^Ū░Ų┌Ą─ąĶŪ¾Ęų╬÷Ż¼▓óī”┐═涎ĄĮyĮYśŗėą┴╦ę╗éĆ│§▓ĮĄ─┴╦ĮŌ║¾Ż¼╬ęéāė├┴╦īóĮ³ę╗ų▄Ą─ĢrķgÅ─╝▄śŗĄ─Å═ļsČ╚Ż¼ęūė├ąįŻ¼┐═æ¶│╠ą“Ė─äė│╠Č╚Ż¼ąį─▄Ż¼ĘĆČ©ąįĄ╚ČÓéĆĮŪČ╚Ū├Č©┴╦ūŅĮKĄ─ĘĮ░ĖĪŻ
╝▄śŗłD╚ńŽ┬Ż║
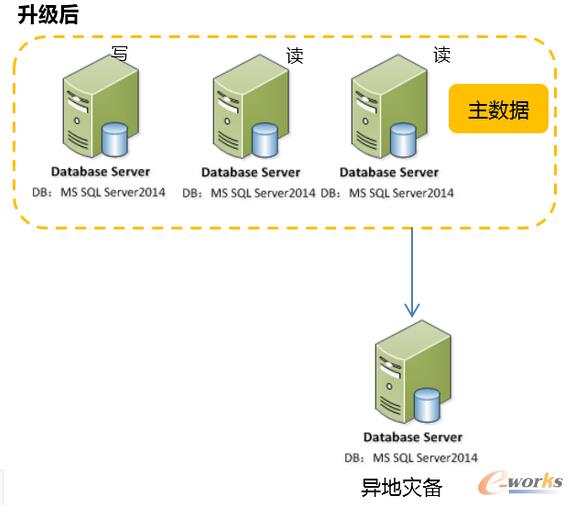
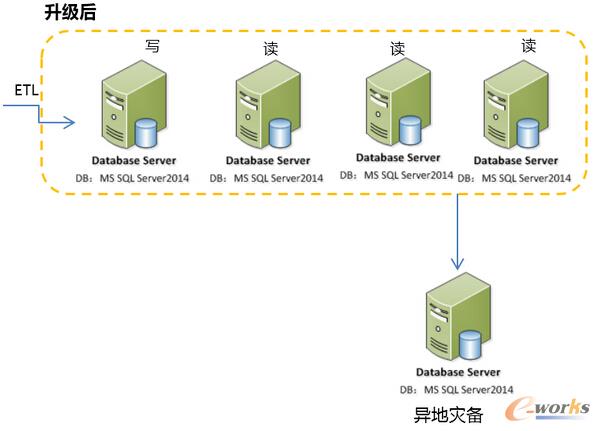
Å─įŁüĒ─Ū├┤Å═ļsĄ─╝▄śŗūā│╔╚ń┤╦ŪÕ╦¼Ą─╝▄śŗŻ¼╩╣ė├AlwaysOn╚Ī┤·Å═ļsĄ─░l▓╝ėåķåŻ¼╩╣ė├AlwaysOnĄ─ų╗ūx╣سcīŹ¼FūxīæĘųļxŻ¼┴Ē═Ō╩╣ė├«ÉĄž×─éõ╣سc╚Ī┤·įŁėąĄ─«ÉĄž░l▓╝öĄō■ÄņŻ¼║▄▓╗Õe░╔ŻĪ▀@ę▓╩Ūė├æ¶ūŅāAŽ“Ą─╝▄śŗŻ¼ę“×ķÅ═ļsČ╚Ą═Ż¼ŽÓī”ĘĆČ©ęūė┌ŠSūoĪŻ▀@└’ę¬ūóęŌŻĪĘ▓╩┬ėą└¹▒žėą▒ūŻĪ꬚f“Ą½╩Ū”┴╦ĪŻ
Ą½╩ŪŻ¼╔²╝ēĖ─äėĄ─│╔▒Š┤¾┤¾╠ß╔²ŻĪ
×ķ╩▓├┤▀@├┤šfŻ┐╬ęéāĮėų°┐┤ŻĪ
įö╝Üš{čą
▀@śėĄ─ę╗éĆÅ═ļsĄ─ŽĄĮyŪ░Ų┌Ą─įö╝Üš{čą╩ŪąĶę¬║▄ķLĢrķgĄ─Ż¼Äū╠ūŽĄĮy▓╗āHāH╩Ū╝▄śŗ╔ŽįOėŗĄ─▒╚▌^Å═ļsŻ¼╣”─▄æ¬ė├ĪóĮė┐┌Ą╚Ė³╩ŪÅ═ļsŻĪŽ┬├µ╩Ūų„ꬥ─ę╗ą®╩ß└Ē▀^│╠Ż║
įŁėąŽĄĮyĮYśŗ
╬ęéā╩ūŽ╚ę¬ī”įŁėąŽĄĮyĄ─įOėŗėą═ĖÅžĄ─┴╦ĮŌŻ¼┐═æ¶į┌ā╔ĄžĘųäeėąę╗éĆöĄō■ųąą─Ż¼╚²╠ūŽĄĮyėą┤¾┴┐Ą─śIäšę¬╩╣ė├Ųõ╦¹ŽĄĮyĄ─öĄō■Ż¼╦∙ęį▀@└’╩╣ė├░l▓╝ėåķå£╩ĢrĢrĄ─░čŲõ╦¹ŽĄĮyųąĄ─öĄō■░l▓╝ĄĮŽĄĮyųąĄ─ę╗éĆöĄō■ÄņŻ¼▓ó╩╣ė├═¼┴xį~ųĖŽ“ėåķåüĒĄ─öĄō■ĪŻ▀@ĘNĮYśŗĮĄĄ═┴╦╩╣ė├µ£ĮėĘ■äšŲ„┐ńīŹ└²╔§ų┴┐ńÖCĘ┐įLå¢Ą─ąį─▄Ž¹║─ŻĪ▓óŪęČÓĘ▌öĄō■ėåķåĄĮČÓéĆų╗ūxĄ─╣سcŻ¼Å─Č°īŹ¼F┴╦ł¾▒ĒĪóĮė┐┌Ą╚śI䚥─ūxīæĘųļxĪŻ
ŽĄĮyī”Ž¾š¹└Ē
ę“×ķę¬ū÷╔²╝ē▀węŲŻ¼╦∙ęįī”Ž¾Ą─š¹└Ē╩Ū║▄ųžę¬Ą─╣żū„Ż¼śIäšī”Ž¾Ą─▀z┬®┐╔─▄Ģ■ĦüĒ▓╗┐╔═ņ╗žĄ─×─ļyŻĪ╔§ų┴┐╔─▄Ģ■ī¦ų┬š¹éĆ╔²╝ēŻ¼╝▄śŗ▓┐╩Ą─╗žØLŻĪÄū╠ūŽĄĮyųą╔µ╝░Ą─ī”Ž¾┴ą▒Ē▀^ė┌²ŗ┤¾Ż¼▒╚╚ńÄż╠¢Äū╩«éĆŻ¼Äū╩«éĆū„śIŻ¼╔Ž░┘éĆ═¼┴xį~Ż¼īŹ└²╝ēė|░lŲ„Ą╚Ą╚…..
Ę■äšŲ„äØĘųŻ║
- ų„Äņī”Ž¾
- ūxīæĘųļxĖ„éĆų╗ūxÄņī”Ž¾
- ░l▓╝ĄĮŲõ╦¹śI䚎ĄĮyĄ─öĄō■Ę■äšŲ„┼õų├ī”Ž¾
- Ųõ╦¹æ¬ė├│╠ą“ī”Ž¾
ī”Ž¾äØĘųŻ║
- öĄō■ÄņÄż╠¢
- µ£ĮėĘ■äšŲ„
- īŹ└²╝ēė|░lŲ„
- ū„śI
- ŽĄĮyģóöĄ
- ŠSūoėŗäØ
- cdc
- BIŽÓĻP
- ═¼┴xį~
- │╠ą“╝»
- Ó]╝■
- ▓┘ū„åT
- ų╗ūxÄņČÓ│÷üĒĄ─╦„ę²ĪóęĢłDĄ╚ī”Ž¾
- Ą╚Ą╚Ą╚
£yįć▀^│╠
┤ŅĮ©£yįćŁhŠ│
╦∙ėąĄ─╔²╝ēĪóĖ▀┐╔ė├ĒŚ─┐£yįćŁh╣ØČ╝╩Ū▒ž▓╗┐╔╔┘Ą─ĪŻ╩ūŽ╚╩Ū£yĘĮ░Ė┼õ║ŽśI䚥─┐╔ąąąįŻ¼ę“×ķū„×ķĄ┌╚²ĘĮ╣½╦Š▓╗─▄ī”ė├æ¶╦∙ėąĄ─æ¬ė├ĻPŽĄŻ¼ŽĄĮy╝▄śŗ┴╦╚ńųĖšŲŻ¼╔§ų┴┐═æ¶ĘĮūį╝║Ą─╣ż│╠Ĥ┐╔─▄ę▓ū÷▓╗ĄĮ▀@ę╗³cĪŻŲõ┤╬╩Ū£yįć╣”─▄į┌ą┬ŁhŠ│Ž┬╩Ūʱ│÷¼F«É│ŻĪŻ▀ĆėąŠ═╩Ūī”╩š╝»▓ó▀węŲĄ─ŽĄĮyī”Ž¾▀Mąąę╗┤╬▓ķ╚▒ča┬®ĪŻ▀@śėę▓┐╔ęį▒M┴┐▒ŻūCŽĄĮy╔ŽŠĆĢr░l╔·╣╩šŽĄ─Ė┼┬╩ŻĪ
£yįćŁhŠ│¤oę╔╩Ū╚╬║╬╔²╝ēĪó╝▄śŗūāĖ³Ą─▒žę¬▓Į¾EŻ¼ę▓ų╗ėąĮø▀^│õĘųĄ─£yįć▓┼─▄ū÷ĄĮą─ųąėąöĄŻ¼▀MČ°īŹ¼F┴Ń╣╩šŽ╔ŽŠĆĪŻ
╔ŽŠĆč▌ŠÜ
╔ŽŠĆč▌ŠÜŻ┐▀@╩ŪéĆ╩▓├┤¢|╬„Ż┐
╩ūŽ╚öĄō■ÄņĄ─▓┘ū„ę╗Č©ę¬┤_Č©┐╔īŹ╩®Ą─Ģrķg┤░┐┌ŻĪ▒ŻūCį┌╣╠Č©Ą─Ģrķg┤░┐┌═Ļ│╔╣żū„║▄ųžę¬Ż¼─Ū├┤▀@Š═╩Ū╔ŽŠĆč▌ŠÜĄ─ūŅ┤¾║├╠ÄŻ¼╬ęéā╩╣ė├£╩éõ│÷Ą─ą┬ÖCŲ„═Ļ╚½─ŻöM╔ŽŠĆĄ─╚½▓┐▓Į¾EŻ¼▓óėøõø├┐éĆ▓Į¾E╩╣ė├Ą─ĢrķgŻ¼┐╔─▄│÷¼FĄ─’LļUŻ¼ūŅ▀tĄ─═Ļ│╔ĢrķgĄ╚Ą╚ĪŻŲõ┤╬┤ŅĮ©═Ļ│╔║¾╬ęéā┐╔ęįė├▀@éĆŁhŠ│Ż©Š═╩Ū═Ļ│╔║¾š²╩ĮŁhŠ│Ą─┼õų├Ż®▀Mąąē║┴”£yįćĪŻ
╔ŽŠĆč▌ŠÜ╩Ūę╗éĆ║▄▒žę¬Ą─▓Į¾EŻ¼Ą½▀@éĆ▓Į¾Eę¬ęĢīŹļHĄ─ŪķørČ°Č©Ż¼▒╚╚ń╔²╝ēĄ─ĘĮ╩ĮŻ¼ŁhŠ│Ą─┼õų├Ą╚ĪŻį┌▀@śėĄ─ę╗éĆĒŚ─┐ųą╬ęéāū÷┴╦ā╔▌åĄ─╔ŽŠĆč▌ŠÜŻĪ
īŹ╩®▀^│╠
ųŲČ©ąį─▄╗∙ŠĆ
▀@śėę╗éĆ┤¾Ą─ūāäėŻ¼öĄō■Äņį┌Ė„éĆļAČ╬Ą─ąį─▄ųĖś╦╩Ū╩▓├┤śėūėĄ──žŻ┐ ▀@└’╬ęéāę└╚╗╩╣ė├ Expert for SQL Server ╣żŠ▀ī”├┐ę╗éĆļAČ╬īŹ╩®Ū░║¾ąį─▄▀Mąąī”▒╚Ż¼▀@śė▓╗āH─▄ī”īŹ╩®Ą─ė░Ēæ▀Mąą▒O┐žŻ¼Ė³─▄ŪÕ╬·ĄžĘų╬÷│÷├┐éĆīŹ╩®ļAČ╬ī”ąį─▄Ą─ė░ĒæŻĪ
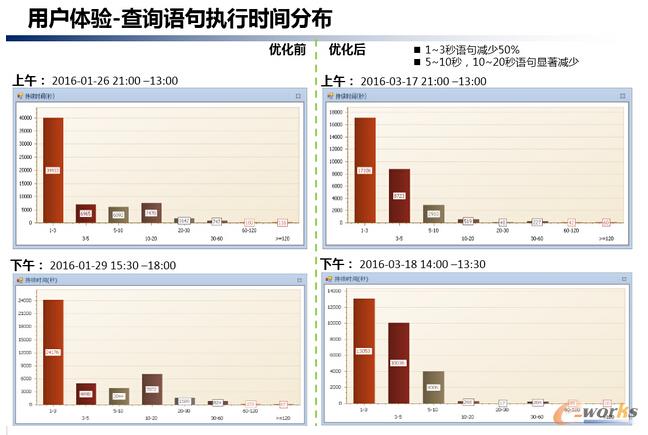
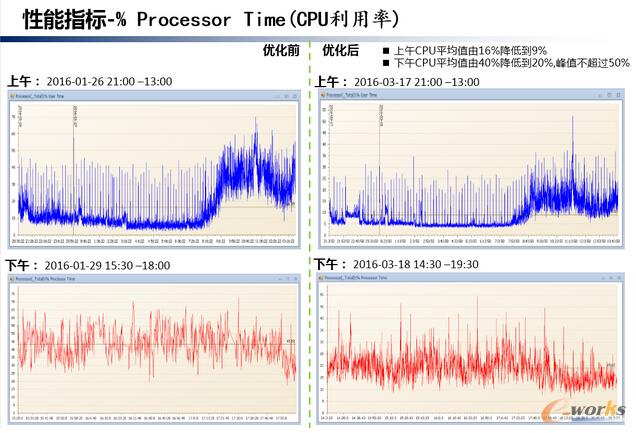
ī”├┐éĆųĖś╦ę▓Č╝ū÷ŽÓæ¬Ą─ī”▒╚Ęų╬÷Ż¼ųĖś╦▒╚▌^ČÓ▀@└’▓╗ę╗ę╗ĮķĮB┴╦Ż¼šłģóęŖā×╗»ŽĄ┴ą╬─š┬Ż║
SQL SERVER╚½├µā×╗»——-Expert for SQL Server į\öÓŽĄ┴ą
ąį─▄ā×╗»
▀@└’Ą─ąį─▄ā×╗»Ż¼╬ęéāų„ę¬ßśī”šZŠõŽĄĮyĄ─ę╗ą®│ŻęÄģóöĄĪó┬²šZŠõ▀MąąĄ┌ę╗▌åĄ─ā×╗»ŻĪ┴Ē═Ōę╗éĆųž³cŠ═╩Ū×ķ┴╦æ¬ī”╔²╝ēĄĮ2014║¾┐╔─▄ūā┬²Ą─šZŠõ▀Mąąš{š¹ŻĪŠ▀¾w╩▓├┤śėĄ─šZŠõ┐╔─▄ūā┬²Ż┐ ▀@éĆ…
- ŽĄĮyĄ─ųž³cšZŠõŻ©ł╠ąąūŅŅlĘ▒Ą─Ż®
- šZŠõÅ═ļsĄ─
- ┤¾├µĘe£yįć
▀@└’×ķ╩▓├┤ę¬į┌╔²╝ēŪ░Š═ū„▀@śėĄ─ā×╗»╣żū„Č°▓╗╩Ū╔²╝ē║¾ŽĄĮy▀\ąąĢrį┌ßśī”┬²Ą─šZŠõ▀MąąĘų╬÷─žŻ┐ ▀@éĆĄ└└Ē║▄║åå╬Ż¼╚ń╣¹╔ŽŠĆ┴╦▓┼░l¼F╚ń╣¹ūā┬²Ą─╣”─▄║▄ČÓŻ¼╗“ūā┬²Ą─╩ŪŅlĘ▒Ą─╣”─▄─Ū├┤╔ŽŠĆĄ─ą¦╣¹Š═╩ŪézéĆūų”╩¦öĪ”ĪŻļm╚╗ėąĄ─┐┤╣┘ų¬Ą└┐╔ęį╩╣ė├╠ß╩Š╗“ĮĄĄ═╝µ╚▌╝ēäeĮŌøQ▀@éĆå¢Ņ}Ż¼Ą½╩Ū▀@ų╗╩Ū╠ž╩Ōł÷Š░Ž┬Ą─śOČ╦╩ųČ╬Ż¼Č°▓ó▓╗╩ŪĮŌøQĄ─Ė∙▒ŠĪŻ╦∙ęįĮ©ūh╚ń╣¹─Ńėą╔²╝ēĄĮ2014Ą─ąĶ꬯¼─Ū├┤▀@śėĄ─ā×╗»╩ųČ╬ę╗Č©ę¬╠ßŪ░ū÷ŻĪ
╔²╝ēĄĮ2014
╔²╝ēöĄō■Äņ═Ļ╚½┐╔ęįīæ│╔║├ÄūŲ¬▓®┐═Ż¼╔§ų┴īæ▒ŠąĪĢ°Č╝┐╔ęį┴╦ŻĪ▀@└’ų╗ū÷║åå╬ĮķĮBŻ¼║═ę╗ą®ę¬ųž³cūóęŌĄ─å¢Ņ}ŻĪ
╔²╝ēĘĮ╩Į
╔²╝ēĘĮ╩Įėą2ĘNŻ║in place ║═side by sideŻ¼▀@└’▓╔ė├Ą─╩Ūside by sideŻĪ ═©╦ūĄžšfŠ═╩Ū£╩éõą┬Ą─Ę■äšŲ„Ż¼░▓čbī”æ¬░µ▒ŠĄ─öĄō■ÄņŻ¼╚╗║¾░čöĄō■▀ĆįŁ╔Ž╚źĪŻside by sideĄ─║├╠ÄŠ═╩Ū╔²╝ē▓╗Ģ■ė░ĒæįŁėąĄ─ŁhŠ│Ż¼╝┤╩╣╩¦öĪę▓─▄ą▐Ė─│╠ą“ųĖŽ“╗ž═╦ĄĮįŁŁhŠ│ŻĪ
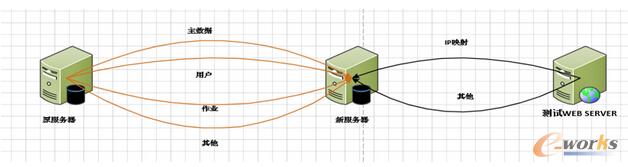
╔²╝ē2014 ūŅ┤¾Ą─ę╗éĆå¢Ņ}
2014 Ą─ą┬╠žąį “ģóöĄ╣└ėŗ” ŻĪ▀@éĆūī╚╦┼dŖ^ėų┐ÓÉ└Ą─ą┬╣”─▄Ģ■ī¦ų┬║▄ČÓšZŠõį┌╔²╝ēĄĮ2014 ║¾ūā┬²Ż¼ę“×ķŪ░├µĄ─ā×╗»ļAČ╬ęčĮøī”▀@▓┐Ęųųž³cĻPūó┴╦Ż¼╦∙ęį▀@▓┐ĘųĄ─å¢Ņ}╗∙▒ŠęčĮøŽ¹£ńŻĪĄ½╩Ū╚fÉ║Ą─Ęųģ^▒ĒŻ©200ČÓéĆĘųģ^Ż®ę└╚╗ī¦ų┬┴╦┼·╠Ä└ĒĄ─ąį─▄ć└ųžå¢Ņ}ŻĪ
╝»╚║┤ŅĮ©
╝»╚║┤ŅĮ©┐╔─▄ø]ėą▀^ČÓĄ─┐╔šfų¦│÷Ż¼š²│ŻäōĮ©╣╩šŽ▐DęŲ╝»╚║Ż¼┤ŅĮ©AlwaysOnĄ╚Ż¼Ą½▀@ŲõųąĄ─╝Ü╣Ø▀Ć╩Ū║▄ČÓĄ─Ż¼▒╚╚ńų┘▓├Ą─ĘĮ╩ĮŻ┐«ÉĄž╣سcĄ─╠ōöMIPįOų├Ż┐╣سcéĆöĄ┼cśI䚥─┼õ║ŽŻ┐Ą╚Ą╚Ą╚Ą─å¢Ņ}Ż¼▀@└’ę▓Š═▓╗ę╗ę╗╝Üšf┴╦ĪŻ
š¹¾w▓Į¾Eųą│õ│Ōų°¤oöĄĄ─╝Ü╣ØŻ¼├┐ę╗éĆ╝Ü╣Ø┐╔─▄Č╝øQČ©ų°ĘĮ░ĖĄ─┐╔ąąąįŻ¼╔²╝ēĪó╝▄śŗūāĖ³Ą─│╔öĪĪŻŽ▐ė┌Ų¬Ę∙▀@└’ų╗┼eÄūéĆ┐╔─▄│ŻęŖĄ─å¢Ņ}šf├„ę╗Ž┬ŻĪ
- CDC╣”─▄┼cAlwaysOnŻ║╣┘ĘĮ╬─Ön╔ŽšfCDC┼cAlwaysOn┐╔ęįīŹ¼F▐DęŲ║¾CDC▓╗ķgöÓŻ¼Ą½╩ŪĮø▀^£yįćCDCū„śIį┌AlwaysOnŪąōQ║¾ČÓ┤╬ł╠ąą╩¦öĪät▓╗Ģ■į┘ę╗┤╬ūįäė▀\ąąŻ¼CDCĄ─logreader║═░l▓╝ėåķåĢrę╗śėĄ─Ż¼Ą½į┌ø]ėą░l▓╝ėåķå┤µį┌Ą─ŪķørŽ┬ų╗ėąCDCū„śIĢ■│÷¼F╔Ž╩÷å¢Ņ}ĪŻĮŌøQ▐kĘ©Ż║┼õų├š{┐žū„śIŻ©╣سcŪąōQū„śI┐žųŲŻ®
- ųžĮ©╦„ę²▓┘ū„Ż║ė╔ė┌┼õų├«ÉĄž╣سcĪŻ╚šųŠųžĮ©ūā│╔å¢Ņ}Ż¼£yįćųąųžĮ©╦„ę²Ą─╚šųŠ┴┐╩Ūå╬ÖCŽ┬╚šųŠ┴┐Ą─║├Äū▒ČŻĪ▀@śėĢ■ī¦ų┬«ÉĄž╚šųŠĻĀ┴ą▀^ķLĪŻĮŌøQ▐kĘ©Ż║╩╣ė├╩ų╣ż─_▒Š▓Ęų╝Ü╗»╦„ę²ųžĮ©Ż¼Ė∙ō■ĻĀ┴ą┤¾ąĪ║═é„▌ö╦┘┬╩┐žųŲ├┐╠ņĄ─╚šųŠ┴┐ĪŻ
- 2014Ž┬šZŠõūā┬²Ż║Š▀¾wŠ═▓╗╝Üšf┴╦Ż¼2014ģóöĄ╣└ėŗ║═200+Ęųģ^▒ĒĮM║Ž«a╔·Ą─šZŠõūā┬²å¢Ņ}ų┴Į±ø]ėą┤░ĖĪŻ─┐Ū░ų╗╩Ū╩╣ė├ę╗ą®ĘĮĘ©▒▄├Ō┴╦▀@éĆå¢Ņ}ŻĪŻ©▀@éĆå¢Ņ}ę▓šłė÷ĄĮĄ─┼¾ėčĮoą®╦╝┬ĘŻ¼ųxųxŻ®
- ų╗ūxĖ▒▒Š╔Žėąīæ▓┘ū„Ż║ė╔ė┌ę╗ą®ł¾▒Ē▓┘ū„╩╣ė├ųąķg┼RĢr▒ĒŻ¼▀@└’┼RĢr▒Ē▓╗╩Ū#temp ▀@ĘNČ°╩Ūšµš²Ą─╬’└Ē▒Ēū„×ķ┼RĢr▒ĒĪŻĮŌøQĘĮ░ĖŻ║ą▐Ė─×ķ┼RĢr▒ĒŻ¼╗“äōĮ©å╬¬ÜöĄō■ÄņŻ©▓╗į┌┐╔ė├ąįĮMųąŻ®Ż¼į┌╩╣ė├═¼┴xį~ųĖŽ“ą┬ÄņīŹ¼Fīæ▓┘ū„ĪŻ
ė÷ĄĮĄ─å¢Ņ}šµĄ─╩ŪĖ„ĘNČÓŻ¼▀@ę▓╩Ū×ķ╩▓├┤šf«ö─ŃĄ─│ŻęÄ╝╝ąg╩ųČ╬Č╝šŲ╬šĄ─Ģr║“Ż¼▓╚▀^Ą─┐ėŠ═╩Ū─ŃĄ─│╔ķL┴╦ŻĪ
┐éĮY Ż║ ╬─š┬ų╗╩Ū║åå╬ĘųŽĒ┴╦ę╗éĆ▌^×ķÅ═ļsĄ─08ĄĮ14Ą─╔²╝ē▓ó┤ŅĮ©Ė▀┐╔ė├Ą─╣żū„Ż¼šµš²Ą─īŹæĒŚ─┐║═ūį╝║┤ŅĮ©Ą─£yį接Įy▀Ć╩Ūėą║▄┤¾Ą─▓ŅäeĪŻĒŚ─┐š¹éĆ╣żŲ┌│ų└m┴╦3éĆį┬Ż¼╦∙ęį▒Š╬─ų╗╩Ū║åå╬Ą─šf├„╦╝┬Ę║═▓Į¾EŻ¼┴Ē═ŌĮķĮB┴╦ÄūéĆ│ŻęŖĄ─┤¾┐ėĪŻĒŚ─┐ųąĄ─ų„ę¬▓Į¾EŻ¼éĆ╚╦šJ×ķ▀@ę▓╩Ūį┌öĄō■ÄņĖ▀┐╔ė├ĘĮ░Ė┤ŅĮ©▀^│╠ųąĄ─▒žę¬▓Į¾EŻ║
1ŽĄĮy▒│Š░š{▓ķ
2śIäšš{蹯¼╔·│╔│§░µĘĮ░Ė
3įö╝Üš{蹯¼ī”Ž¾š¹└Ē
4£yįćŁhŠ│┤ŅĮ©
5ŽĄĮy£yįćŻ¼┤_Č©ĘĮ░Ė
6╔ŽŠĆč▌ŠÜŻ¼┤_Č©Ģrķg┤░┐┌
7ē║┴”£yįć
8š²╩Į╔ŽŠĆ
9╔ŽŠĆ║¾▒O┐ž
10ĮŌøQå¢Ņ}Ż¼ųŲČ©ŠSūoĘĮ░Ė
┤╦ĒŚ─┐┐╔ęįšf╩Ū▒╚▌^ć└Ė±Ą─ū±čŁ┴╦ŽÓĻP╣▄└ĒĄ─ś╦£╩Ż¼į┌╚²éĆį┬Ą─īŹ╩®ųąŻ¼╬ęéā▒³│ą▀@“ĘĆČ©┤¾ė┌ą¦┬╩”Ą─╦╝ŽļŻ¼╣żū„╝Ü╗»ĄĮ├┐ę╗▓ĮŻ¼├┐ę╗▓ĮČ╝ėąįö╝ÜĄ─šf├„Ż¼ūŅĮK▒ŻūC┴╦╚²╠ūŽĄĮyĄ─╔ŽŠĆ▀\ąą┴Ń╣╩šŽŻĪ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.lukmueng.com/
▒Š╬─ś╦Ņ}Ż║öĄō■ÄņĖ▀┐╔ė├īŹæ░Ė└²Ī¬Ī¬-╝▄śŗā×╗»
▒Š╬─ŠWųĘŻ║http://m.lukmueng.com/html/support/11121520057.html