▒Ŗ╦∙ų▄ų¬Ż¼▀@╩Ūę╗éĆą┼ŽóĢr┤·———╝┤│õØMöĄō■Ą─Ģr┤·ĪŻļSų°╬’┬ōŠWĄ─æ¬ė├┼c░lš╣Ż¼╚╦éā═╗╚╗░l¼FŻ©╩┬īŹ╔ŽįńŠ═┤µį┌Ż®Ż¼öĄō■┴┐Äū║§│╔ųĖöĄ╝ēį÷ķLĪŻėą▀@śėę╗ĮMöĄō■Ż║╚½Ū“├┐╠ņėą43 ā|▓┐ļŖįÆ║═20 ā|╬╗╗ź┬ōŠWė├æ¶į┌╔·│╔öĄō■Ż¼▓ó┼c300 ā|éĆRFID ś╦║×║═öĄ░┘Ņw╚╦įņąląŪ├┐├ļČ╝į┌▓╗öÓ░l╦═Ė³ČÓą┼╠¢╚┌║Žį┌ę╗ŲŻ¼ŲõųąŻ¼Twitter ├┐╠ņŠ═Ģ■į÷╝ė12 TB Ą─öĄō■———╚½╬─▒ŠŻ¼Ūę├┐┤╬ūŅČÓ╠Ē╝ė140 éĆūųĘ¹Ż¼Č°▀@ų╗╩ŪöĄō■į┌öĄ┴┐╝ē╔Žī”┤¾╝ęĄ─ę╗ĘNø_ō¶ĪŻ▒Š╬─īóÅ─ęįŽ┬ÄūéĆ▓┐ĘųŠ═┤¾öĄō■▀MąąėæšōĪŻ
1 ┤¾öĄō■üĒį┤╝░öĄ┴┐
╠ߥĮöĄō■Ż¼ŽÓą┼ITÅ─śI╚╦åT╩ūŽ╚ŽļĄĮĄ─╩ŪöĄō■ÄņĪóöĄō■é}ÄņĄ╚╝╝ągŻ¼«ģŠ╣▀@╩Ūę╗ĘNų┴Į±╚į╚╗╩«Ęų┴„ąąŪęš╝ō■ų„ī¦Ąž╬╗Ą─╝╝ągĪŻĄ½šłėøūĪŻ¼▀@ą®╝╝ąg╩ŪśŗĮ©į┌ĻPŽĄą═öĄō■Äņ└Ēšō╗∙ĄA╔ŽĄ─Ż¼Š▀ėą├„’@Ą─ĮYśŗ╗»╠žš„Ż¼ōQčįų«Ż¼┤µā”į┌öĄō■ÄņĪóöĄō■é}ÄņųąĄ─öĄō■╩Ū╬ęéā═©▀^Ęų╬÷ĪóĮ©─Żų«║¾║Y▀xų«║¾│÷üĒĄ─ĪóūįšJ×ķėąęŌ┴xĄ─öĄō■ĪŻČ°į┌▀@éĆ▀^│╠ųąŻ¼ęčĮø▐ŚēĄ¶┴╦įSČÓūįšJ×ķ¤oęŌ┴xĄ─öĄō■Ż¼šµĄ─ø]ėąęŌ┴xå߯┐┤░Ė«ö╚╗╩ŪʱȩĄ─ĪŻĄ½×ķ╩▓├┤ę¬▐Śē─žŻ┐įŁę“║▄║åå╬Ż¼ęįŪ░Ą─╝╝ągŚl╝■▓╗į╩įS┤µā”╚ń┤╦²ŗ┤¾Ą─öĄō■┴┐ĪŻ
ļSų°╬’┬ōŠWĖ┼─ŅĄ─╠ß│÷Īóæ¬ė├║═░lš╣Ż¼├┐╠ņÅ─RFIDĪóé„ĖąŲ„Īó┐žųŲŲ„ĪóųŪ─▄įOéõųąČ╝Ģ■«a╔·║Ż┴┐öĄō■ĪŻō■ĮyėŗŻ¼į┌2000 ─ĻŻ¼╚½Ū“┤µā”┴╦800 000 PB Ą─öĄō■Ż╗ŅAėŗĄĮ2020 ─ĻŻ¼▀@ę╗öĄūųĢ■▀_ĄĮ35 ZB[3]ĪŻ╦∙ęįŻ¼┐╔ęįĄ├│÷▀@śėĄ─ĮYšōŻ║┤¾öĄō■Å─üĒŠ═╩Ū┤µį┌Ą─Ż¼ų╗╩Ūę“×ķ╝╝ągŚl╝■Ą─Ž▐ųŲČ°ø]ėąųžęĢ╗“╩Ū╣╩ęŌęÄ▒▄Č°ęčĪŻ
2 ┤¾öĄō■ŅÉą═
ęįŪ░▒Ż┤µĄ─öĄō■ŅÉą═ų„ę¬╩ŪĮYśŗ╗»öĄō■ĪŻ╚╗Č°Ż¼▓óĘŪ╦∙ėąĄ─öĄō■Č╝╩Ū┐╔ęįĮYśŗ╗»Ą─Ż¼ō■ĮyėŗŻ¼┐╔ĮYśŗ╗»öĄō■———╝┤┐╔ęį┤µā”į┌öĄō■ÄņĄ╚é„ĮyŽĄĮyŻ©ų„ę¬╩ŪųĖĻPŽĄą═öĄō■Äņ«aŲĘŻ®ųąĄ─öĄō■š╝öĄō■┐é┴┐Ą─20%ū¾ėęŻ╗Ųõ╦¹80%Ą─öĄō■▓╗─▄ų┴╔┘╩Ū▓╗▒Ńė┌┤µā”ė┌é„ĮyĄ─ŽĄĮyųąŻ¼ę“×ķŲõĮYśŗą╬╩Į╩ŪĘŪĮYśŗ╗»Ą─╗“š▀╩Ū░ļĮYśŗ╗»Ą─Ż©╚ń╬─▒ŠĪóé„ĖąŲ„öĄō■Īóę¶ŅlĪóęĢŅlĪó╩┬äš╝░Ąžš─Żą═ŅÉĄ─äėæBöĄō■Ą╚ĘŪĻPŽĄą═öĄō■Ż®ĪŻ
╦∙ęįŻ¼Å─▀@éĆĮŪČ╚╔ŽüĒųvŻ¼┤¾öĄō■Ą─ŅÉą═Å─ĮYśŗŅÉą═╚ļ╩ų┐╔ęįĘų×ķĮYśŗ╗»Īó░ļĮYśŗ╗»ĪóĘŪĮYśŗ╗»öĄō■3ŅÉĪŻ
3 ┤¾öĄō■╠Ä└Ē╦┘Č╚╝░ĘĮ╩Į
├µī”╚ń┤╦²ŗ┤¾Ą─öĄō■┴┐Īóęį╝░žSĖ╗Ż©ų┴╔┘▓╗į┘╩Ūå╬ę╗Ą─Ż®Ą─öĄō■Ż¼▓╗ļyŽļŽ±Ż¼ī”ė┌▀@ą®öĄō■Ą─╠Ä└Ē╦┘Č╚īóĢ■│╔×ķŲ¾śIæ¬ė├ĪóČ┤▓ņĻPµI╩┬╝■Ą─Ų┐ŅiĪŻ▒M╣▄─┐Ū░▀Ćø]ėąĄ├ĄĮŠ▀¾wĄ─┐╔Č╚┴┐Ą─ųĄüĒšf├„▀@éĆå¢Ņ}Ż¼Ą½ōQéĆĮŪČ╚üĒ┐╝æ]Ż¼Š═╚š│Ż╣żū„ųą╦∙╩╣ė├Ą─┤µā”Ų„Ą─┤µā”─▄┴”ĪóCPU Ņl┬╩Ą─ūā╗»╝░▓╗Ė▀Ą─╣żū„ą¦┬╩Ż¼Š══Ļ╚½┐╔ęįšf├„öĄō■į÷ķL╦┘┬╩ī”öĄō■╠Ä└Ē╦┘Č╚Ą─ė░ĒæĪŻ
Į©ūhōQéĆĮŪČ╚üĒ┐╝æ]▀@éĆå¢Ņ}ĪŻļSų°╬’┬ōŠWĢr┤·Ą─ĄĮüĒŻ¼RFIDĪóé„ĖąŲ„Ą╚«a╔·Ą─ą┼Žó┴„īóī¦ų┬«a╔·┤¾┴┐Ą─é„ĮyŽĄĮy¤oĘ©╠Ä└ĒĄ─│ų└möĄō■┴„ĪŻšł└╬ėøę╗³cŻ¼¼Fį┌╠Ä└ĒĄ─╩ŪPB ╝ēĄ─öĄō■┴„Ż¼Č°ĘŪTB ╝ēĄ─Ż¼īóüĒę¬╠Ä└ĒĄ─╩ŪZB ╝ē╔§ų┴ėą┐╔─▄Ė³Ė▀ĪŻ╦∙ęįŻ¼ąĶę¬┐╝æ]ßśī”öĄō■«a╔·Īó┴„äėĄ─╦┘Č╚Č°▀MąąĄ─öĄō■╠Ä└ĒĘĮ╩ĮĄ─ūāĖ’Ż¼╚ń┴„öĄō■╠Ä└ĒŻ╗▓╗į┘╩Ūå╬╝āĄž╠Ä└Ēé„ĮyŽĄĮyųąĄ─┼·┴┐öĄō■ĪŻ
4 ┤¾öĄō■─Żą═
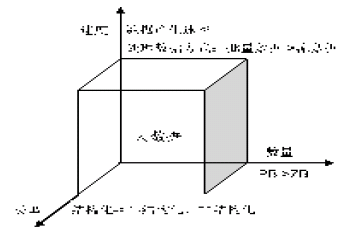
┤¾öĄō■Ą─▒Š┘|śŗĮ©╚ńłD1 ╦∙╩ŠĪŻ
łD1 ┤¾öĄō■─Żą═
Å─łD1 ─Żą═▓╗ļy┐┤│÷Ż¼┤¾öĄō■Å─▒Š┘|╔ŽüĒųv░³║¼öĄ┴┐ĪóŅÉą═Īó╦┘Č╚3 éĆŠSČ╚Ą─å¢Ņ}Ż¼╩┬īŹ╔ŽŻ¼ę¬ŽļÅ─Ė∙▒Š╔Žģ^äe▀@3 éĆŠSČ╚╩Ū▓╗┐╔─▄Ą─ĪŻę“×ķŻ¼┤¾öĄō■Ė┼─ŅĄ─╠ß│÷╩Ūį┤ė┌╝╝ągĄ─░lš╣Ż║╩ūŽ╚Ż¼ęįŪ░Ą─┤µā”Ų„╝╝ąg▓╗┐╔─▄ų¦│ų╚ń┤╦║Ż┴┐öĄō■Ą─┤µį┌Ż╗ļSų°┤µā”Ų„╝╝ągĄ─░lš╣Ż¼▓┼╩╣Ą├║Ż┴┐öĄō■Ą─┤µā”ųØu│╔×ķ┐╔─▄Ż¼Ą½ę▓ĦüĒ┴╦┴Ē═Ōę╗éĆå¢Ņ}———öĄō■┤µā”ŅÉą═žSĖ╗ŲüĒŻ╗ļSų°öĄō■┤µā”ŅÉą═Ą─žSĖ╗╝░öĄō■Ą─į÷ķL╦┘Č╚╝ė╦┘å¢Ņ}Ż¼ī¦ų┬┴╦╠Ä└ĒöĄō■╦┘Č╚Ą─å¢Ņ}Ż¼Å─Č°ę²Ų┴╦╠Ä└ĒöĄō■╝╝ągĄ─Ė’├³ąįūāĖ’ĪŻ
5 ┤¾öĄō■╠Ä└Ē╝╝ąg╝░▓▀┬į
Į³─ĻüĒŻ¼ĻPė┌┤¾öĄō■╠Ä└Ē╝╝ągĄ─╠Įėæę╗ų▒▓╗öÓŻ¼▀@ĘĮ├µūŅŠ▀┤·▒ĒąįĄ─Š═╩ŪHadoop ┐“╝▄ Ż¼Ųõ▒Š┘|╩Ūę╗éĆė├ė┌Ęų╬÷┤¾öĄō■╝»Ą─ÖCųŲŻ¼▓╗ę╗Č©╬╗ė┌öĄō■┤µā”ųąŻ¼┐╔ęįöUš╣ĄĮ¤oöĄéĆ╣سcŻ¼╠Ä└Ē╦∙ėą╗Ņäė║═ŽÓĻPöĄō■┤µā”Ą─ģfš{ĪŻHadoop ĘĮĘ©Į©┴ó╣”─▄ĄĮöĄō■Ą──Żą═Ż¼Č°ĘŪé„ĮyĄ─öĄō■ĄĮ╣”─▄Ą──Żą═Ż¼▀@śėŠ═┐╔ęįÅ─┐╔öUš╣ąį║═Ęų╬÷Ą─ĮŪČ╚░l¼Fį°ĮøÄū║§▓╗┐╔─▄Ą─┤¾öĄō■╠Ä└Ēūā│╔┐╔─▄ĪŻ
ė╔ė┌Hadoop ▓╝╩Ą─Å═ļsąį╝░▓╗ĘĆČ©ąįŻ¼╩╣Ųõæ¬ė├ĄĮ─┐Ū░×ķų╣▀Ć▓╗╩Ū╩«ĘųÅVĘ║Ż¼Ą½¤ošō╚ń║╬Ż¼Ųõ×ķ┤¾öĄō■╠Ä└Ē╠ß╣®┴╦ę╗ĘN═ŠÅĮ║═ĘĮ╩ĮĪŻIBMį┌Hadoop Ą─╗∙ĄA╔Ž░lš╣┴╦GPFSŻ©General Parallel File SystemŻ¼═©ė├▓óąą╬─╝■ŽĄĮyŻ®¤o╣▓ŽĒ╝»╚║╝░ŽÓĻP╝╝ągŻ¼╠ß╔²┴╦ņoų╣┤¾öĄō■╠Ä└Ēą¦┬╩Ż╗┤╦═ŌŻ¼▀Ć╠ß│÷┴╦SPLŻ©StreamsProcessing LanguageŻ¼┴„╠Ä└ĒšZčįŻ®,╩╣Ą├ī”┴„öĄō■Ą─╠Ä└Ē│╔×ķ¼FīŹ▓ó┤¾┤¾╠ß╔²┴╦īŹļH╣żū„ą¦┬╩ĪŻ
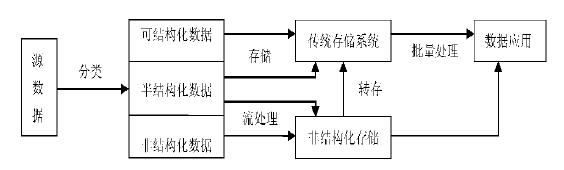
ßśī”╠Ä└Ē┤¾öĄō■╝╝ągŻ¼Ą├│÷łD2 ╦∙╩ŠĄ─┤¾öĄō■╠Ä└Ē▓▀┬įĪŻ
łD2 ┤¾öĄō■╠Ä└Ē▓▀┬į
╚ńłD2╦∙╩ŠŻ¼ī”ė┌┤¾öĄō■Ą─╠Ä└Ē▓▀┬į┐╔ū„╚ńŽ┬└ĒĮŌŻ║ó┘░┤ššŅÉą═▀MąąĘųŅÉ╠Ä└ĒŻ╗ó┌ī”ĘųŅÉöĄō■▀MąąĘųŅÉ┤µā”╗“┴„╠Ä└ĒŻ╗ó█ī”Įø┴„╠Ä└ĒĄ─ĘŪĮYśŗ╗»┤µā”▓┐Ęų┐╔▐D┤µĄĮé„Įy┤µā”ŽĄĮyŻ¼ę▓┐╔ų▒Įė╔·│╔öĄō■æ¬ė├Ż╗ó▄ī”é„Įy┤µā”ŽĄĮy▀Mąą┼·┴┐╠Ä└Ē╔·│╔öĄō■æ¬ė├ĪŻ
6 ĮY╩°šZ
Š═┤¾öĄō■Ą─üĒį┤ĪóöĄ┴┐ĪóŅÉą═Īó╠Ä└Ē╦┘Č╚Īó╠Ä└ĒĘĮ╩ĮĄ╚ĘĮ├µī”┤¾öĄō■▀Mąą┴╦╠ĮėæŻ¼Įo│÷┴╦┤¾öĄō■─Żą═Ż╗═¼Ģrī”┤¾öĄō■─Żą═Ą─3éĆŠSČ╚▀MąąĮŌ╬÷Ż¼▓ó║åå╬ĮķĮB┴╦┤¾öĄō■╠Ä└Ē╝╝ągĪŻī”ė┌öĄō■╣żū„š▀Ż¼ė╚Ųõ╩ŪöĄō■Ęų╬÷ĤĻPūóĄ─ī”Ž¾╝░╠Ä└Ē╝╝ąg║═▓▀┬įėąę╗Č©Ą─ę²ī¦ū„ė├ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.lukmueng.com/
▒Š╬─ś╦Ņ}Ż║ĮŌ╬÷┤¾öĄō■
▒Š╬─ŠWųĘŻ║http://m.lukmueng.com/html/support/11121810361.html